Explore top 10 tips to secure your open-source projects now. Read More
×How Open Source SIEM Architectures Scale Beyond Single-Server Deployments
3 - 5 min read
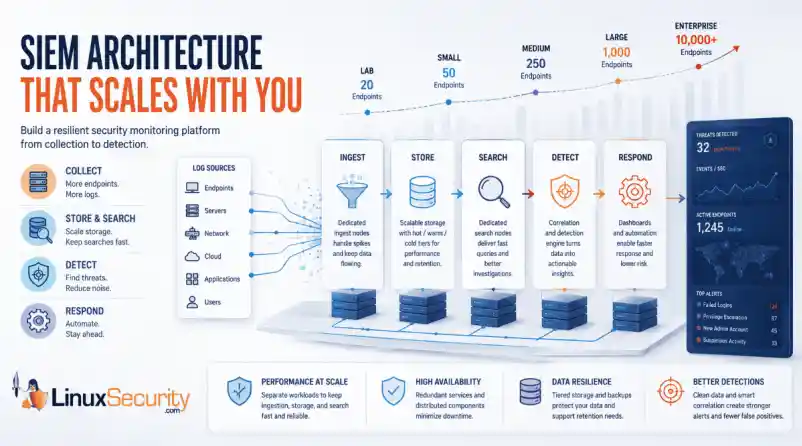
Building a SIEM is easier than scaling one. Most open-source deployments start as a simple "all-in-one" server. It is easy to set up, but that design rarely survives the transition from a lab to a production workload.
A SIEM watching 20 endpoints is not doing the same job as one watching 500. More endpoints mean more logs; more logs require more storage; more storage makes search heavier. Eventually, the very architecture that made your lab easy to deploy becomes the reason your production system fails. Production environments diverge from homelab setups because collection, storage, search, and analytics scale at different rates.
Why Open Source SIEM Tools Struggle to Scale
A typical first SIEM deployment runs everything on one virtual machine. This works  for small environments because the workload is low. However, as the organization grows—adding authentication logs, firewall records, and cloud audit events—that architecture cracks.
for small environments because the workload is low. However, as the organization grows—adding authentication logs, firewall records, and cloud audit events—that architecture cracks.
A Wazuh deployment monitoring 25 endpoints might generate thousands of events per hour, while a much larger deployment with 500 endpoints can process far more events in the same period. The architecture that worked on a single VM struggles with storage growth, indexing delays, and slow searches.
SIEM Architecture Pattern #1: Scaling Log Management and Search
Most hobby deployments run collection, indexing, storage, and search on the same server because it is simple. Mature environments eventually separate these workloads because each one scales differently.
Dedicated ingest nodes receive and process incoming logs before they are indexed. Separating ingestion from storage and search prevents a spike in incoming data from slowing down your investigations or delaying your detections.
|
If You Experience... |
Immediate Architectural Change |
|
Slow searches |
Move search workloads to separate, dedicated resources |
|
Storage filling quickly |
Implement hot/warm/cold storage tiers |
|
Delayed alerts |
Separate detection workloads from ingestion nodes |
|
Event backlogs |
Scale ingestion capacity horizontally |
SIEM Architecture Pattern #2: Design for High Availability and Failure
Production SIEM architectures assume hardware failures, maintenance windows, and service outages will occur. The goal is not preventing failures; the goal is ensuring one failed component does not take the entire platform offline.
Following the Wazuh architecture, environments typically move from a single manager to clustered deployments with redundant managers, distributed indexers, and load-balanced services.
Failure Prioritization:
|
Priority |
Component |
Reason |
|
1 |
Storage/Indexing |
Historical data is often the hardest thing to recover |
|
2 |
Manager/Controller |
Processes incoming events and runs detection logic |
|
3 |
Collection Services |
Prevents data loss during network outages |
|
4 |
Dashboard |
Useful for investigation, but not mission-critical |
SIEM Architecture Pattern #3: Building a Security Monitoring Pipeline
Dashboards are only the view layer. Mature deployments treat the SIEM as a data pipeline. According to the Microsoft Sentinel architecture, data collection, analysis, retention, and automation are key parts of the pipeline. 
The biggest threat to this pattern is inconsistent data. If your logs aren't normalized—for example, if one source calls a field user and another calls it account_name—your detection rules will fail regardless of how powerful your infrastructure is.
Decide: Pick five critical log sources. Verify that usernames, timestamps, hostnames, and source IPs are formatted consistently across all of them. Fix these "data-messy" spots before adding more dashboards.
SIEM Architecture Pattern #4: Improving Threat Detection at Scale
More logs do not automatically mean better security. Effective SIEM architecture best practices focus on what happens after data arrives: correlation and response.
If you are building your first SIEM, prioritize detections that identify common attacker behavior rather than rare edge cases.
|
Detection |
Why It Matters |
|
Failed logins followed by success |
Identifies potential password guessing |
|
New administrator account |
Identifies potential privilege escalation |
|
Login from a new system |
Identifies potential stolen credentials |
|
Security tool disabled |
Identifies potential attacker cleanup |
Decide: Build five reliable detective rules before adding five new log sources. A small number of working alerts is always more valuable than a massive pile of logs that no one is reviewing.
What Leading SIEM Tools (Elastic, Wazuh, and Microsoft ) Get Right About Architecture
Major platforms prove that architectural maturity is the only way to scale.
- Elastic: Their reference architectures focus heavily on workload separation. Scaling collection, indexing, storage, and search independently prevents one workload from overwhelming the platform.
- Wazuh: Their guidance shows how environments move to clustered deployments with redundant services and distributed indexers.
- Microsoft Sentinel: They treat the SIEM as a data platform where collection, retention, and automation are treated with the same importance as the alerts themselves.
- SentinelOne: Their approach emphasizes that detection and response are the ultimate goals, rather than just collecting as much data as possible.
A Security Operations Roadmap for Growing SIEM Deployments
Do not try to copy an enterprise architecture on day one. Build the next layer your environment actually needs.
|
Environment Size |
Focus Pattern |
|
1–50 endpoints |
Reliable collection and basic detection logic. |
|
50–250 endpoints |
Separate search resources from ingestion workloads. |
|
250–1,000 endpoints |
Implement storage tiers and service redundancy. |
|
1,000+ endpoints |
Full distributed architecture and automation pipelines. |
Scaling a SIEM is not about making the design complicated. It is about ensuring your collection, storage, search, and detection do not all depend on one fragile box. The organizations that scale successfully rarely start with perfect architectures. They gradually separate workloads, improve data quality, add redundancy, and invest in detection engineering as requirements grow. The sooner those patterns are introduced, the easier it becomes to scale without constantly rebuilding the platform.
Related Reading
- Open Source SIEM Strategies Address Challenges for Small Teams
- OSSEC for Linux: Enhancing Monitoring and Risk Posture Management
- Linux Privilege Escalation Patterns and Mitigation Strategies
- Enhancing Linux Security With Ansible Automation Techniques
- Comprehensive Linux Security Tools and Hardening Best Practices 2026
- AI-Driven Tools Enhance Linux Security Against Emerging Threats


Powered By

Linux Security - Your source for Top Linux News, Advisories, HOWTOs and Feature Releases
QUICK LINKS
subscribe to newsletters!
Like staying secure? So do we.
Sign up for updates, tips, and alerts!